
はじめに
Amazon Bedrock のナレッジベースにCSVをそのまま登録すると、ファイル全体が1つのテキストとして扱われてしまいます。
しかし、メタデータ設定を活用すると、CSVを「1行=1ドキュメント」として解析し、各行にメタデータを付けたうえでベクトルDBへ登録できます。FAQ形式のデータを扱う場合など、精度の高いRAGを構築したいときに非常に有効な手法です。
この記事では、Aurora PostgreSQL をベクトルストアとして手動で構築し、ナレッジベースと紐づけるまでの手順を、実際に遭遇したエラーの対処も含めてまとめます。
構成イメージ
S3(ソースデータ)
├── sample.md
├── sample.md.metadata.json ← ファイル単位のメタデータ
├── sample.csv
└── sample.csv.metadata.json ← 行単位のメタデータ(今回のポイント)
↓ 同期
Amazon Bedrock ナレッジベース
↓ ベクトル化して保存
Aurora PostgreSQL(pgvector)前提
- AWS アカウントと適切な IAM 権限があること
- 対象の VPC・サブネットが構成済みであること
- S3 バケットが作成済みであること
全体の流れ
- Aurora PostgreSQL を作成し、ベクトルDB用のテーブルを構築する
- Bedrock ナレッジベースを作成し、Aurora と紐づける
- メタデータファイルを作成してS3にアップロードする
- 同期して動作確認する
Aurora の作成
DB クラスターを作成する
- マネージドコンソールから、
Aurora and RDSを開きます。 -
データベースを作成するを選択します。 - 下記の表に合わせて各項目を入力します。
- 記載ないものは、デフォルトで可です。
- 入力が終わったら、
データベースの作成を選択します。
| 項目① | 項目② | 設定値 |
|---|---|---|
| エンジンのオプション | エンジンのタイプ | Aurora (PostgreSQL Compatible) |
| データベース作成方法を選択 | データベース作成方法を選択 | フル設定 |
| テンプレート | 開発/テスト | |
| クラスタースケーラビリティタイプ | Serverless v2 | |
| 容量の範囲 | 0~8 | |
| 非アクティブ後に一時停止 | 00:05:00 | |
| 設定 | エンジンバージョン | PostgreSQL 17.4 |
| DB クラスター識別子 | 例: sample-kb-db | |
| 認証情報の設定 | マスターユーザー名 | 例: postgres |
| 認証情報管理 | AWS Secrets Manager で管理 | |
| 暗号化キーを選択 | aws/secretsmanager(デフォルト) | |
| クラスターストレージ設定 | 設定オプション | Aurora スタンダード |
| 可用性と耐久性 | マルチ AZ 配置 | Aurora レプリカを作成しない |
| 接続 | コンピューティングリソース | EC2 コンピューティングリソースに接続しない |
| ネットワークタイプ | IPv4 | |
| Virtual Private Cloud (VPC) | <対象のVPC> | |
| DB サブネットグループ | <対象のサブネット> | |
| パブリックアクセス | なし | |
| VPC セキュリティグループ (ファイアウォール) | 新規作成 | |
| 新しい VPC セキュリティグループ名 | <任意の値> 例:aurora-kb-sg | |
| アベイラビリティーゾーン | <対象のアベイラビリティーゾーン> | |
| 認証機関 - 任意 | <デフォルト> | |
| RDS Data API | ✅RDS Data API の有効化 | |
| タグ - オプション | <任意の値> | |
| 以降はデフォルトでOKです。 |
RDS Data API を有効にしておかないと、クエリエディタから接続できません。
- 1~2分で作成完了するので、次の作業に移動します。
クエリエディタで Aurora に接続する
- AWS マネジメントコンソール
- Aurora and RDS → 左メニューの クエリエディタ
- 「データベースに接続」を選択します。
- 下記の表に合わせて各項目入力します。
- 「データベースに接続します」を選択します。
| 項目 | 値 |
|---|---|
| データベースインスタンスまたはクラスター | 作成した Aurora クラスターを選択 |
| データベースユーザー名 | Secrets Manager ARN と接続する |
| Secrets manager ARN | データベース→設定→マスター認証情報 ARNの値 |
| データベースの名前を入力 | postgres |
ベクトルDB用のデータベースを準備する
接続できたら、以下の順番でSQLを実行します。
SELECT datname FROM pg_database;CREATE DATABASE bedrock;SELECT datname FROM pg_database;- 作成後、再度一覧を確認して
bedrockが追加されていれば成功です。
bedrock データベースに切り替える
- 「データベースを変更する」を選択します。
- 下記の表に合わせて各項目入力します。
| 項目 | 値 |
|---|---|
| データベースインスタンスまたはクラスター | 作成したAurora |
| データベースユーザー名 | Secrets Manager ARN と接続する |
| Secrets manager ARN | データベース>設定>マスター認証情報 ARNの値 |
| データベースの名前を入力 | bedrock |
テーブルとインデックスを作成する
以下のSQLを順番に実行します。
CREATE EXTENSION IF NOT EXISTS vector;CREATE SCHEMA bedrock_integration;CREATE TABLE bedrock_integration.bedrock_knowledge_base (
id UUID PRIMARY KEY,
chunks TEXT,
embedding VECTOR(1024),
metadata JSONB,
custommetadata JSONB
); embedding の次元数は、後で選択する埋め込みモデルに合わせる必要があります。Titan Text Embeddings V2 は 1024次元 です。
Bedrock のナレッジベース接続時に、各カラムへのインデックスが必須です。
-- chunks(全文検索用)
CREATE INDEX ON bedrock_integration.bedrock_knowledge_base
USING gin (to_tsvector('simple', chunks));
-- embedding(ベクトル近傍探索用)
CREATE INDEX ON bedrock_integration.bedrock_knowledge_base
USING hnsw (embedding vector_cosine_ops);
-- custommetadata(JSONB 検索用)
CREATE INDEX ON bedrock_integration.bedrock_knowledge_base
USING gin (custommetadata);SELECT table_schema, table_name
FROM information_schema.tables
WHERE table_schema = 'bedrock_integration';-
bedrock_knowledge_baseが表示されれば、DB側の準備は完了です。
ナレッジベース作成
- Amazon Bedrockを開きます。
- 左のメニューで「ナレッジベース」を選択します。
- 「作成」を選択します。
- 「ベクトルストアを含むナレッジベース」を選択します。
- 以下の表を参考に設定してください。
- 「ナレッジベースを作成」を選択します。
| 項目 | 項目 | 値 |
| ナレッジベースの詳細を指定 | ナレッジベース名 | 例: sample-kb |
| ナレッジベースの説明 - オプション | サンプル用のナレッジベースです | |
| IAM 許可 | 新しいサービスロールを作成して使用 | |
| サービスロール名 | 例: sample-kb-role | |
| データソースを選択 | S3 | |
| タグ | <任意の値> | |
| データソースを設定 | データソース名 | 例: sample-ds-kb-s3 |
| データソースの場所 | この AWS アカウント | |
| S3 の URI | 自身の値 | |
| 解析戦略 | Amazon Bedrock デフォルトパーサー | |
| チャンキング戦略 | <任意の値> | |
| データストレージと処理を設定 | 埋め込みモデル | Titan Text Embeddings V2 or Embed Multilingual v3 |
| ベクトルストアの作成方法 | 既存のベクトルストアを使用 | |
| ベクトルストア - 新規 | Aurora | |
| Amazon Aurora DB クラスター ARN | <Amazon リソースネーム (ARN)の値> | |
| データベース名 | bedrock | |
| テーブル名 | bedrock_integration.bedrock_knowledge_base | |
| シークレット ARN | <マスター認証情報 ARNの値> | |
| ベクトルフィールド名 | embedding | |
| テキストフィールド名 | chunks | |
| Bedrock マネージドメタデータフィールド | metadata | |
| カスタムメタデータ - オプション | custommetadata | |
| プライマリキー | id |
- 完了まで待ちます。
メタデータ作成
ナレッジベースは、ソースファイルと同名の .metadata.json ファイルをS3に置くことで、メタデータを自動的に取り込みます。
ファイル名のルール:
sample.md → sample.md.metadata.json
sample.csv → sample.csv.metadata.json
サンプルのデータ
Markdown ファイルのメタデータ(ファイル単位)
sample.md
# 情報セキュリティ基本規程(架空) v1.0
## 第1条(目的)
本規程は、情報資産の漏えい・改ざん・滅失を防止し、業務継続性を確保することを目的とする。
## 第2条(認証情報の管理)
1. パスワードは第三者に共有してはならない。
2. パスワードは推測されにくいものを設定し、定期的に更新する。
3. 多要素認証が提供される場合は有効化する。
## 第3条(端末の利用・持ち出し)
1. 会社貸与端末は業務目的で使用する。
2. 社外持ち出しは承認を得たうえで行い、紛失・盗難時は速やかに報告する。
3. 公共ネットワーク利用時は、会社が指定する安全な接続手段を利用する。
## 第4条(外部送信・共有)
1. 社外への送信・共有は、機密区分と社外提供可否を確認したうえで実施する。
2. 原則として共有リンク(期限・権限制御)を利用する。
3. メール添付が必要な場合は、手順に従い適切な保護を施す。
## 第5条(データ保管)
1. 業務データは会社が指定する保管場所に保存する。
2. 個人クラウドや私物媒体への保存を禁止する。
## 第6条(インシデント報告)
1. 誤送信、紛失、マルウェア疑い等を認知した場合、速やかに所定窓口へ報告する。
2. 事実関係(対象、時刻、影響範囲)を整理し、指示に従って対応する。
## 附則
本規程は2026年4月1日から施行する。sample.md.metadata.json
{
"metadataAttributes": {
"doc_type": "internal_policy",
"policy_name": "情報セキュリティ基本規程(架空)",
"policy_version": "1.0",
"owner": "情報セキュリティ担当(架空)",
"audience": "全社員",
"confidentiality": "internal",
"tags": ["セキュリティ", "端末", "メール", "インシデント"]
}
}- Markdown ファイルはファイル全体に対してメタデータが付きます。
CSV ファイルのメタデータ(行単位)
CSVファイルにメタデータを設定するのが今回のポイントです。documentStructureConfiguration を使うことで、CSVを「1行=1ドキュメント」として登録できます。
サンプルCSV(sample.csv)
ID,PolicyName,PolicyVersion,Section,Audience,Status,LastUpdatedDate,Tags,Content
faq_001,情報セキュリティ基本規程(架空),1.0,第2条(パスワード),全社員,Active,2026-03-23,"セキュリティ,パスワード,運用","question: パスワードはどのくらいの頻度で変更しますか?, answer: 原則90日以内に変更します。変更が難しい事情がある場合は、管理者に申請してください。"
faq_002,情報セキュリティ基本規程(架空),1.0,第3条(端末の持ち出し),全社員,Active,2026-03-23,"セキュリティ,端末,持ち出し","question: 社外にノートPCを持ち出すときの手続きは?, answer: 持ち出し申請を行い、承認後に持ち出してください。公共Wi‑Fi利用時はVPN接続を必須とします。"
faq_003,情報セキュリティ基本規程(架空),1.0,第4条(メール添付),全社員,Active,2026-03-23,"セキュリティ,メール,添付","question: 取引先にファイルをメール添付してよいですか?, answer: 機密区分を確認し、許可されている場合のみ送信します。原則は共有リンク(期限付き)を利用します。"
faq_004,情報セキュリティ基本規程(架空),1.0,第6条(インシデント報告),全社員,Active,2026-03-23,"セキュリティ,インシデント,報告","question: 誤送信に気づいたら最初に何をすればいいですか?, answer: まず上長と窓口(情報セキュリティ担当)へ連絡し、事実(宛先/内容/時刻)を共有します。自己判断で削除依頼だけして終わらせないでください。"
faq_005,情報セキュリティ基本規程(架空),1.0,第7条(データ保管),全社員,Active,2026-03-23,"セキュリティ,保管,共有","question: 社内資料を個人のクラウドストレージに置いてもいいですか?, answer: 禁止です。会社が指定する保管場所(社内ストレージ/許可されたクラウド)を利用してください。"メタデータファイル(sample.csv.metadata.json)
{
"metadataAttributes": {
"dataset": "policy_faq_sample"
},
"documentStructureConfiguration": {
"type": "RECORD_BASED_STRUCTURE_METADATA",
"recordBasedStructureMetadata": {
"contentFields": [
{ "fieldName": "Content" }
],
"metadataFieldsSpecification": {
"fieldsToInclude": [
{ "fieldName": "ID" },
{ "fieldName": "PolicyName" },
{ "fieldName": "PolicyVersion" },
{ "fieldName": "Section" },
{ "fieldName": "Audience" },
{ "fieldName": "Status" },
{ "fieldName": "LastUpdatedDate" },
{ "fieldName": "Tags" }
]
}
}
}
}設定のポイント:
-
contentFields:ベクトル化する列(今回はContent列)を指定します -
fieldsToInclude:検索時に参照できるメタデータとして付与する列を指定します -
type: "RECORD_BASED_STRUCTURE_METADATA":この指定があることで行単位の処理になります
S3 へアップロードして同期する
- 上記ファイルをS3バケットにアップロードします
- ナレッジベースの画面から「同期」を実行します
動作確認
- 「ナレッジベースをテスト」を選択します。
- モデルを選択して、下記の質問を送信します。
質問1:パスワードはどのくらいの頻度で変更する必要がありますか?
パスワードはどのくらいの頻度で変更する必要がありますか?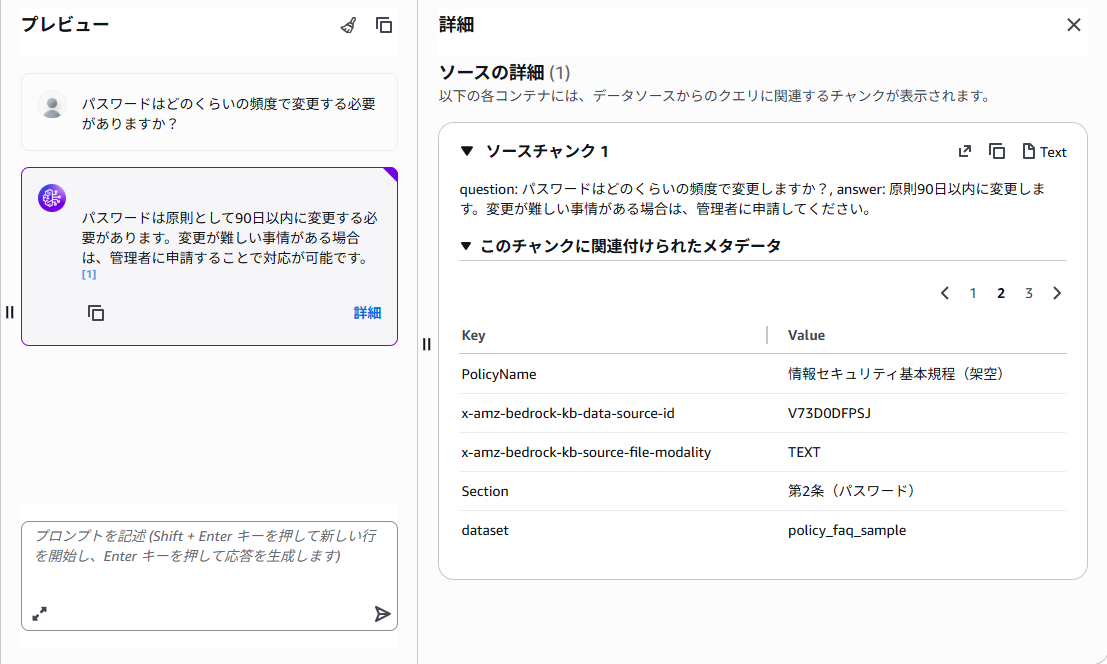
-
Sectionやdatasetなどのメタデータが反映されているのが確認できます。 - 元データがCSVなので、行単位でベクトルDBに登録されていることが確認できます。
質問2:公共Wi‑Fiで業務しても大丈夫ですか?
公共Wi‑Fiで業務しても大丈夫ですか?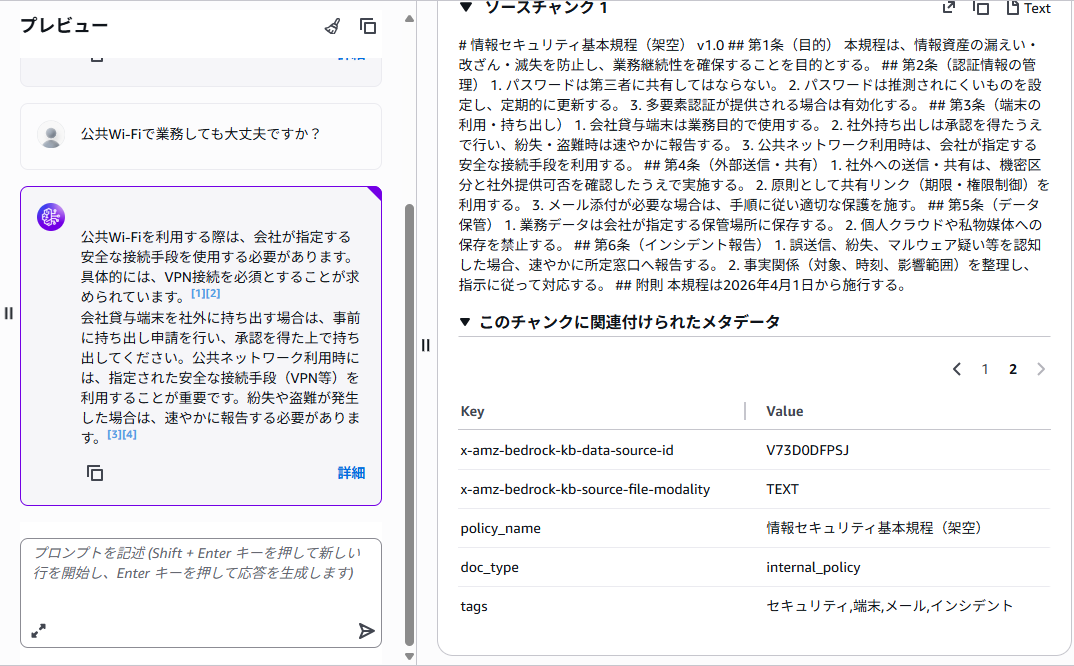
- こちらは Markdown ファイル全体に紐づいたメタデータが返ります。
リソースの削除
検証が終わったら、以下のリソースを削除します。
| リソース | 削除の注意点 |
|---|---|
| Bedrock ナレッジベース | ナレッジベース画面から削除 |
| Aurora PostgreSQL | • インスタンス → クラスターの順に削除。 • スナップショットと自動バックアップは不要であれば残さない |
| IAM ロール | ロール名で検索して削除 |
| Secrets Manager | Aurora 削除後に削除 |
| S3 バケット | 他で使用していなければ削除 |
エラーと対処法
実際に構築した際に遭遇したエラーと、その原因・対処をまとめます。
NoSuchEntityException: Policy ... does not exist
Policy AmazonBedrockSecretsPolicyForKnowledgeBase_sample-kb-role does not exist.原因: IAM ロールを新規作成した場合、初回作成時にポリシーが存在しないタイミングでエラーが出ることがあります。
対処: 時間をおいて再試行するか、ポリシーを手動でアタッチします。
id column has text data type, but expected uuid
原因: id カラムの型を TEXT で作成していた。
対処: テーブルを作り直し、id カラムの型を UUID にします。
-- 修正版
id UUID PRIMARY KEY,embedding column has vector(1536) data type, but expected vector(1024)
原因: 埋め込みモデルの次元数とテーブルの次元数が一致していない。Titan Text Embeddings V2 は 1024次元なのに、テーブルを 1536次元で作成していた。
対処: 使用する埋め込みモデルの次元数に合わせてテーブルを作り直します。
| 埋め込みモデル | 次元数 |
|---|---|
| Titan Text Embeddings V2 | 1024 |
| Cohere Embed Multilingual v3 | 1024 |
| Titan Embeddings G1 - Text | 1536 |
chunks column must be indexed
The knowledge base storage configuration provided is invalid...
chunks column must be indexed.原因: chunks カラムに全文検索用インデックスが作成されていない。
対処:
CREATE INDEX ON bedrock_integration.bedrock_knowledge_base
USING gin (to_tsvector('simple', chunks));embedding column must be indexed
原因: embedding カラムに近傍探索用インデックスが作成されていない。
対処:
CREATE INDEX ON bedrock_integration.bedrock_knowledge_base
USING hnsw (embedding vector_cosine_ops);custommetadata column must be indexed
原因: custommetadata カラムに JSONB 用インデックスが作成されていない。
対処:
CREATE INDEX ON bedrock_integration.bedrock_knowledge_base
USING gin (custommetadata);Tips: Bedrock がナレッジベースと Aurora の接続を検証する際、3つのインデックス(全文検索・ベクトル・JSONB)がすべて存在しないとエラーになります。テーブル作成と同時に作成しておくのが確実です。